
お奉行様、濡れ衣でございまする! – 下町ディープラーニング #4
みなさんこんにちは。dottの清水です。
第3回の「負けるが勝ちよ」では、正解率の高いAIモデルを使うだけでは現場のニーズにフィットしないという話をしました。「サルベージ」という「捨てられたものの中から必要なものを見つけ出す作業」が現場でとても負担が多く、正解することよりこの作業を減らすように調整する必要があるというところまでが前回のお話です。
今回はどのようにサルベージ作業を元々の約6.2%から約0.2%まで下げたかという話をしたいと思います。
サルベージを少なくするために
前回も出てきた図ですが、以下のように「NewsPic」が「偽陰性」の判定をするニュース記事がサルベージの対象です。
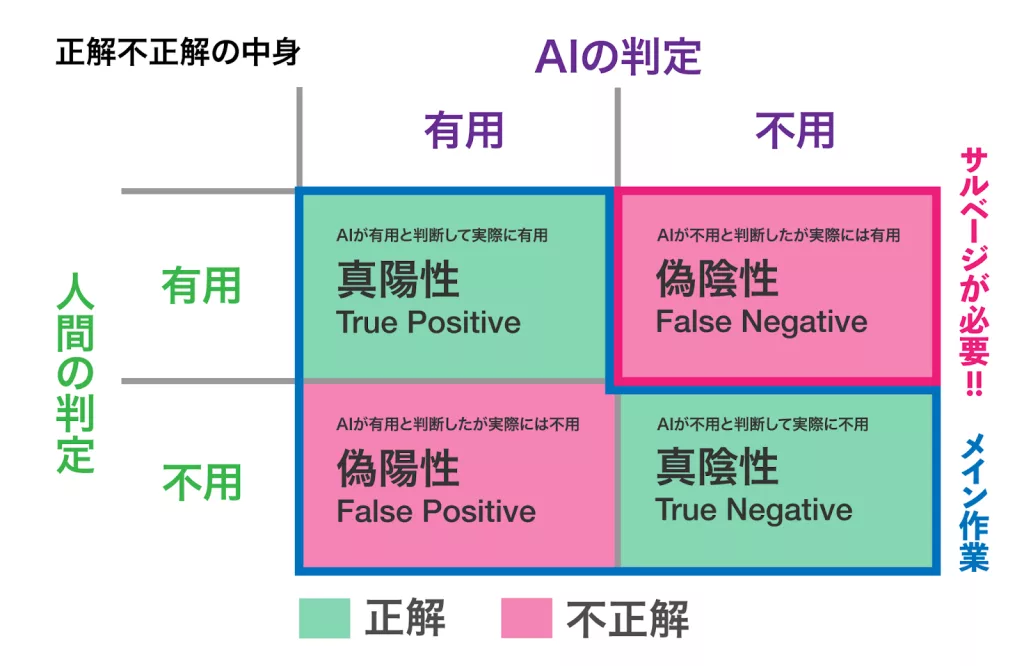
NewsPicでは当初Word2VecやDoc2Vecを用いて開発がスタートしましたが、BERTの登場により当時ははBERTを使用してニュース記事の本文の「クラス分類」を行うようになりました。クラス分類とは「ニュースをカテゴリに分類するようなタスク」で、機械学習ではとても一般的に行われる手法です。画像を与えて、犬か猫か鳥かを判定する、みたいなものもクラス分類ですね。
NewsPicにニュース記事を入力すると、1〜4のカテゴリーの中にある過去のニュースと類似度の高いものを返します。僕は大人になったのでカテゴリーの内容の詳細については割愛しますが、4つ目が不用なニュースを入れるカテゴリーになっています。
疑わしきは罰せず
一般的なクラス分類のニューラルネットワークの場合、最後の出力は全部足して1になるようなそれぞれのカテゴリの類似度というような形で出てきます。以下のような形です。
1: 20%
2: 35%
3: 5%
4: 40%(不用なニュース)
最も類似度が高いカテゴリーは4なので、不用なニュースである可能性が最も高い結果ですね。素直にこの結果を信じれば、このような判定をしたニュースは不用なニュースに分類するべきです。
正解率は高い方がいいというのはもちろんそうですが、このような結果でも「4ではない」とするに有意な差が見られない場合は、1〜3の中で最も類似度の高いカテゴリーに分類します。そうすることで、結果的に正解率の数値は悪化するものの、サルベージ作業を減らすことに特化したモデルを作成することができます。
つまり疑わしいのであれば、不用なものだとして捨てない方針です。
%を件数にしてみると
調整を入れない状態で正解率が85%だったモデルでも、サルベージ率は元々の6.2%から約4.0%に下がっていました。Doc2Vec時代はサルベージ率が4.5%程度だったので、BERTを導入するだけで早速恩恵を受けたこともわかりました。
しかし6.2%から4.0%に低下したと言うと「なんだかサルベージ率も少なくなったなぁ」と感じますが、6.2%は「16件に1件」くらいはサルベージが必要で、4.0%では「25件に1件」のサルベージが必要だということです。こう書くと「少なくはなっているが、そこそこある」と感じるから不思議ですよね。
そのためNewsPicではこのサルベージ率を約0.2%、つまり500件に1件程度に調整したモデルを採用しています。その結果、正解率は82%と低くなりましたが、このバランスの使用感が良さそうだということを、担当の方や現場の方のフィードバックを受けながら調整しました。
現場の声
サルベージ作業を減らすというような目的の他にも、現場によってはさまざまな意志・意向があると思います。疑わしくても罰さない今回のような方法ではなく、疑わしければ罰するような調整をした方が好まれる場合もありますよね。
dottではそんな声を大切にしながら、AIのラスト1mを埋める為に、日々素敵な仲間と楽しく仕事をしています。興味のある方は是非一緒に働けると嬉しいです。
これにて一件落着
4回にわたってNewsPicの話をしてきましたが、この一連のお話はこれで終わりです。少しは皆さんに有意義な話ができたかな、と思いますがいかがでしたでしょうか。
そういえば、dottのブログを見ているお客さんから「清水さんはレンゲが怖いんですか?」と聞かれることがたまにあります。dottの週刊漫画は多くの方に読んでいただいているみたいで、レンゲにうなされているエピソードがかなり印象に残ってるみたいですね。
「なんでうなされるようになったか」ですか?
その詳しい話はまた、次回の記事で。
